Projects
On this page you can find all the projects available for Friday!
Project 1 - Social Network Analysis
Problem Statement
This project is about using Python to visualise and analyse network data in Python. In this case we will focus on loading using Python to analyse social network data (eg. Twitter, Facebook, etc.). The idea is to build networks that show how people in multidisciplinary fields are connected on social networks (i.e. who follows whom). This will allow us to identify the key individuals who connect independent groups that make up a multidisciplinary subject matter (eg. biologist, geologists, marine experts, policy makers, etc. who are involved with climate change).

Project goals
- Load data from static files/an API
- Build and visualise a network
- Perform simple analysis on this network
Datasets
Publicly available social network data from Twitter/Facebook/etc.
Project 2 - Analysing Metadata of Publications
Problem Statement
This project is about analysing the metadata of academic publications.
Project goals
- Get the publications related to that journal or topic of interest
- Perform some sort of metadata analysis on the publications. For instance, we could:
- analyse keyword occurrence within a certain category/topic of interest
- analyse keyword cooccurrence within a category
- construct a graph to visualise the similarity between publications of a givencategory
Datasets
This data is available via APIs from certain publishers (e.g. Elsevier).
Project 3 - Optimisation in Python
Problem Statement
This project will focus on learning to use perform convex optimisation in Python. We will mainly be using the cvxopt library to perform convex optimisation given an objective function and a set of constraints. We could then use this to perform some experiments on toy datasets.
Project goals
- Learn to use cvxopt (or other) library to perform convex optimisation in Python
Project 4 - Influenza Outbreak Analysis
Problem Statement
This project aims to analyse influenza outbreak profiles. Specifically we will learn to use different data analysis and clustering methods to cluster countries based on outbreak profiles. Given these groups, one of the challenges is to then visualise this high-dimensional data in Python.
Project goals
- Load data from static files
- Learn to perform clustering in Python
- Visualise high-dimensional data
Dataset
WHO database of influenza outbreak worldwide for the past 20 years
Project 5 - Building a spam filter
Problem Statement
Using a public database, build a classifier that can classify junk emails
Project goals
- Import data from SpamAssassin public corpus
- Select features
- Build a binary classifier to decide if an email is spam or not
- Uses numpy, regular expressions and nltk
Datasets
SpamAssassin public corpus
Project 6 - Visualising Molecule Data
Problem Statement
In this project, we will learn how to load data from text files into Python, create visualisations of the data and finally combine these images to create a video. In problems based on reaction engineering we can get text files in which time and amount of molecules can be stored. If we have 3 or 4 species in our system and denote them with a distinct colour, it would be very interesting to create videos showing the increment and decrement of those species over time. The most common tool to describe production/deduction of a population is by plotting time vs. amount of molecules. However, it would also be very fascinating to describe that process through videos.
Project goals
- Load data from text files into Python
- Find a way to visualise the data
- Combine the visualisations from multiple text files to create a video
Project 7 - Proteomic Interaction Map
Problem Statement
I propose to create a proteomic interaction map. Using protein interaction data available online, the project would be:
Project goals
- to find a way to read this dataset with Python; and
- to write a tool that can be used to visualise the interaction between individual proteins.
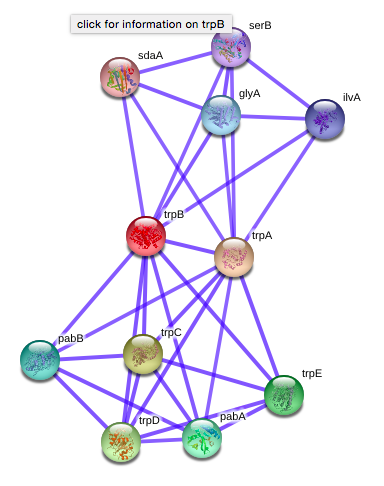
Datasets
Available online.